
急速に普及が進む生成AI(Generative AI)は、ビジネスの現場においてもその活用が本格化しています。文章作成、データ要約、プログラムの自動生成など、従来は人手で行っていた知的業務を支援するツールとして、大きな注目を集めています。
特にChatGPTに代表される大規模言語モデル(LLM:Large Language Model)は、汎用性が高く、非エンジニアでも直感的に扱える点から、多くの企業で活用の検討が始まっています。
しかしその一方で、生成AIは従来の情報システムとは異なる特性を持ち、AI固有の新たなリスクを伴います。本記事では、生成AI(LLM)の仕組みと利用上の留意点を概観した上で、AI導入におけるリスクやガバナンスのあり方について整理します。
生成AI(LLM)の仕組み
LLMは、インターネット上の膨大な文章や文献、プログラムコードなどを学習データとして取り込み、言語の構造やパターンを統計的に学習することで、人間と自然に会話できるモデルとして構築されています。
学習の際には、収集したデータを「トークン」と呼ばれる単位に分解します。トークンとは、わかりやすく言えば単語や句読点、短いフレーズのような最小単位で、モデルは「このトークンの後には、どのトークンが来るか」という確率を大量に分析します。
生成AIの仕組みは非常にシンプルで、「次に来るトークンを予測する」ことを繰り返すだけです。たとえば、「情報セキュリティの基本は…」といった入力に対して、モデルは過去の学習データをもとに「リスクアセスメント」や「脆弱性管理」などの語句を予測し、文脈に合った自然な文章として出力します。
生成AI(LLM)のモデルとは
生成AIの文脈でよくモデルという言葉が出てきます。モデルとは例えば「ChatGPT-4o」などですが、具体的にはこの「学習結果」がモデルです。このモデルに「情報を取り出すエンジン」を組み合わせることで、ユーザの指示(プロンプト)に答えるのです。
<LLMの仕組み>
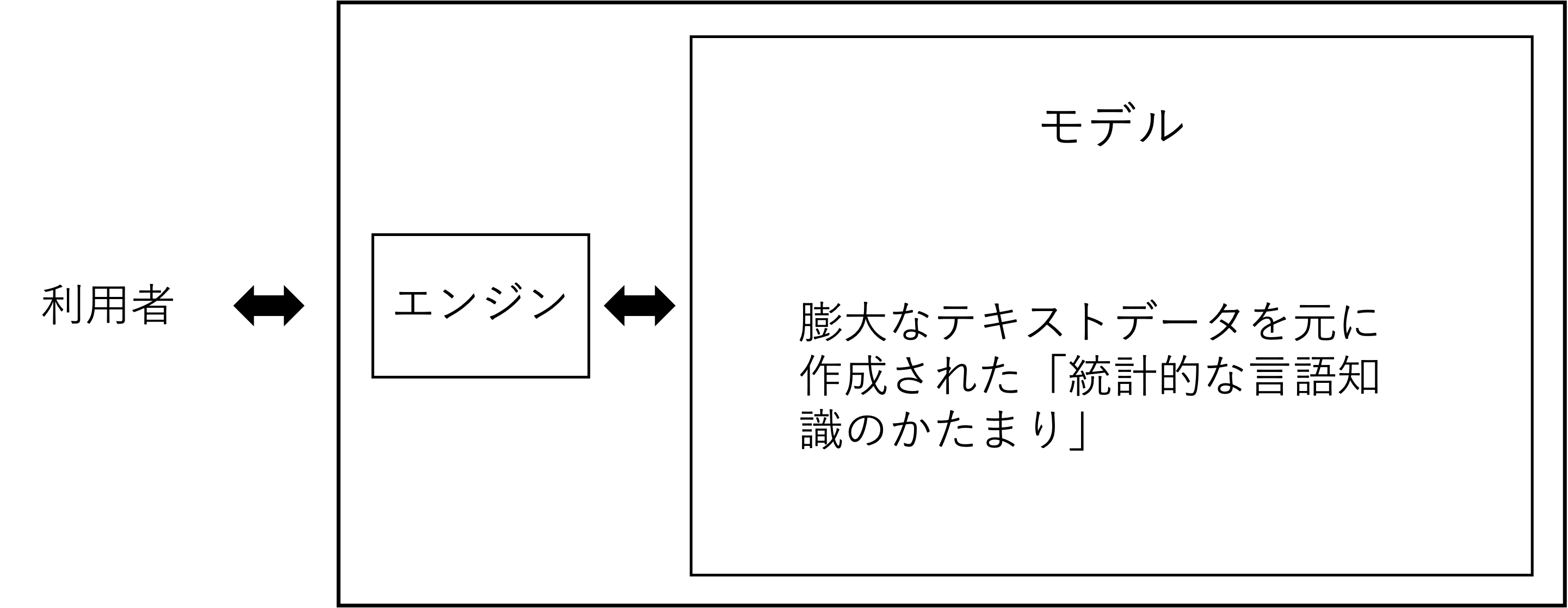
ここで重要な点はモデルがステートレス(stateless)であるということです。つまり、モデルは一度のやり取りが終われば、それ以前の会話内容を内部に記憶することはありません。一見すると「前の話を覚えている」ように見えるかもしれませんが、それはWebサービスなどが過去のやり取りを毎回まとめてモデルに渡しているからです。モデルそのものは常に“初対面”の状態で応答しています。
よく、「プロンプトに入力した内容が学習に使われてしまうのでは」という話を聞きますが、モデルの成り立ちを理解すれば、それは杞憂であることがわかります。ただし、Webサービス側にはプロンプトに入力した内容が保存されていますので、情報漏洩のリスクがないわけではありません。
<LLMの仕組み>

自社のデータを学習させて、自社仕様のモデルを構築することも可能です。それには、以下の3 つの方法がありますが、詳しくは省略します。
- Fine-tuning
- In-context Learning
- Retrieval-Augmented Generation
AI導入に潜むリスク
生成AIの導入は、業務効率の向上や創造性の支援など、企業にとって多くのメリットをもたらします。一方で、思わぬリスクを引き起こす可能性があります。
-
- 情報漏洩
- 通常、プロンプトに入力した内容は学習には使われませんが、外部サーバ上で処理されるため、意図せずセンシティブな情報が第三者に渡るリスクがあります。
-
- 出力内容の信頼性
- 生成AIは、あくまで「もっともらしい出力を予測する」仕組みです。そのため、出力された内容に誤り、バイアス、あるいは技術的な欠陥や脆弱性が含まれる可能性があります。
-
- ブラックボックス化と説明責任
- 生成AIの出力プロセスは極めて複雑で、なぜその回答に至ったのかを説明できないことが少なくありません。特に、法務・財務・人事など意思決定の正当性が求められる業務で利用する場合、この「説明不能性」は大きな問題となります。さらに、最近注目されているAIエージェントのような、自律的に複数のタスクを連続実行できる仕組みを持ったAIの場合は、「暴走リスク」や「制御困難性」というリスクが加わります。
-
- 法的リスク・著作権・知的財産
- 生成AIが出力する文章や画像、コードには、第三者の著作物や知的財産が含まれている可能性があります。特に、商用利用を前提とする場合は、その出力物の権利帰属や利用可能範囲を事前に確認しないと、著作権侵害やライセンス違反といった法的リスクに発展しかねません。 現行の日本法では、生成AIの学習過程における著作物の利用は、原則として合法です。ただし、生成されたコンテンツが特定の著作物と酷似していた場合には、著作権侵害と判断される可能性があります。また、米国ではフェアユースか否かをめぐる訴訟が続いており、EUでは学習は原則合法ですが、著作権者には学習に使われることを拒否する権利があります。
-
- オートメーションバイアス(AI依存)と判断力の低下
- AIの出力は高い自然性を持つため、人間が過信してしまう傾向があります。これを「オートメーションバイアス(自動化バイアス)」と呼びます。たとえば、生成された内容を「AIが言っているから正しいだろう」と無批判に受け入れてしまうと、判断力の低下や誤った意思決定につながるおそれがあります。
AI導入に必要なガバナンスと対策
生成AIを安全かつ効果的に活用していくためには、単にツールを導入するだけでは不十分です。AI固有のリスクに対応するガバナンス体制の整備や、運用上のルール・体制づくりが不可欠です。
-
- 利用ポリシーと社内ルールの整備
- まず重要なのは、生成AIの利用目的・範囲・禁止事項を明確に定めた社内ポリシーの策定です。例えば以下のような項目を含めると効果的です:
- 機密情報・個人情報を含む入力の禁止
- 商用利用可否や成果物の取り扱い方針
- 社外サービス(例:ChatGPTなど)と社内限定AIの使い分けルール
- 利用履歴の記録・モニタリング体制
-
- 出力内容の検証とレビュー体制の確立
- 生成AIの出力は、必ずしも正確・安全・中立であるとは限りません。したがって、業務に活用する際には「人間によるチェックを通す」ことが必要です。特に以下のようなケースでは、第三者レビューや自動テストとの併用が有効です:
- コード生成:セキュリティレビュー/静的解析ツールとの併用
- 文書生成:用語チェック、機械翻訳フィードバック、差別表現フィルター
- データ要約:出典付きでの裏付け確認、重要情報の欠落検知
-
- 技術的制御と環境設計(サンドボックス、フィルター)
- AIエージェントや外部APIと連携した自動処理タスクでは、以下のような想定外の動作を防止するための技術的制御が必要です:
- 外部接続・API利用の範囲を制限
- コマンド実行系タスクにはサンドボックス環境を適用
- 出力に対するフィルタリング(例:NGワード、フォーマット強制)
- 実行前の「確認ステップ」の強制挿入
-
- 契約・利用サービスにおけるリスク評価
- 外部の生成AIサービスを利用する場合、サービス提供者のプライバシーポリシー・利用規約・データ取り扱い方針を精査することが不可欠です。 具体的には:
- 入力内容が学習に使われないこと
- データ保存期間や保存場所(リージョン)の確認
- 出力物の権利帰属と商用利用可否
- セキュリティ基準(SOC 2、ISO 27001など)への準拠
-
- 社内教育と継続的なリスクレビュー
- 生成AIは進化が速く、利用方法やリスクも変化し続けます。そのため、継続的な教育と見直しサイクルを組み込むことが重要です。
- 啓発研修・eラーニング
- 定期的なユースケースレビューとリスクアセスメント
まとめ
生成AIは、単なる業務効率化の手段にとどまらず、企業の意思決定や創造活動を大きく変えるポテンシャルを持った技術です。しかしその導入には、AI特有のリスク構造を理解し、従来の情報セキュリティやコンプライアンスの枠組みを超えたガバナンス設計が求められます。
これからの企業に求められるのは、AIを「禁止する」か「自由に使わせるか」の二択ではなく、戦略的に管理・活用していくためのルールづくりと体制整備です。
生成AIの可能性を最大限に活かすためにも、セキュリティ、法務、経営の各視点からバランスの取れたガバナンスを実現していくことが、これからの重要な経営課題といえるでしょう。



北尾 辰也
サイバーセキュリティコンサルタント。三菱UFJ銀行で12年間サイバーセキュリティに従事し、2022年4月にフリーランスとして独立。現在はサイバーセキュリティに関するコンサルティングやアドバイザー業務を行うとともに、国土交通省最高セキュリティアドバイザーや日本シーサート協議会専門委員、⾦融ISAC個⼈賛助会員として活動している。